近日,我校澳门沙金在线平台程池老师团队与英国伯明翰城市大学计算Muhammad Afzal教授在国际知名期刊《Information Sciences》(T1, IF=8.233)上共同发表学术论文《CNN-Fusion: "CNN-Fusion: An Effective and Lightweight Phishing Detection Method Based on Multi-Variant ConvNet"》。论文的第一作者Musarat Hussain(中文名:胡文硕)是我校2020级巴基斯坦籍硕士研究生,通讯作者是程池老师。

网络钓鱼是一种利用社会工程和技术欺骗来诱导互联网用户泄露敏感信息的网络犯罪。恶意URL地址是网络犯罪分子常用的策略,以欺骗受害者进入钓鱼网站并谋取利益。据统计,每年由于网络钓鱼所造成的金融损失和信息泄露,价值在数十亿美元左右。网络钓鱼骗局正不断增加,因此需要快速、精准和低成本的预防措施。
过去,网络钓鱼的检测依赖于黑名单,但黑名单并不全面,也缺乏对新生成恶意URL地址的检测能力。最近,机器学习被广泛用于检测恶意网址的攻击,其中最常见的方法是通过提取URL地址的词汇属性来分析各种特征,然后采用支持向量机、梯度提升和随机森林等机器学习模型去预防攻击。但这些方法存在缺陷,无法记录语义或顺序模式,也需要人工提取URL特征,增加了计算和操作的开销,而且无法在训练期间处理未见过的特征并泛化到测试数据。
为了应对这些挑战,该论文提出了CNN-Fusion,这是一种基于字符级卷积神经网络(CNN)的有效且轻量级的钓鱼网站检测方法,它从原始URL中提取多级特征,而不需要一些专业领域知识或任何第三方服务来帮助检测恶意的URL地址。该论文的基本想法是并行部署多个具有不同大小内核的单层CNN变体,以提取多级特征。相比于具有固定内核大小的多个顺序层,具有不同内核大小的单层CNN能更有效地捕捉文本模式,这是由于不同的内核宽度可以检测输入URL中的不同模式。例如,一个小的内核可以检测局部模式,但一个较大的内核却可以检测全局模式。该模型采用了被证明在正则化方面非常有效的SpatialDropout1D,并利用了时序最大池化操作,显著提高了其鲁棒性和整体性能。 下图描绘了该模型的整体架构。
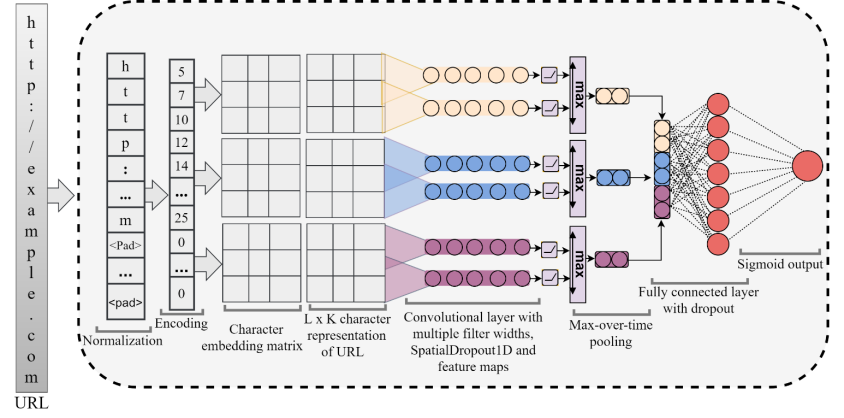
CNN-Fusion:论文中提出的模型架构
据实验结果表明,相较于现有基于深度学习的方法,该论文提出的方法训练时间减少了5倍,内存消耗更少。在五个不同的数据集和AI生成的恶意URL上,平均检测准确率超过了99%。
论文下载地址https://authors.elsevier.com/a/1giEW4ZQEBrkf
资料提供:程池
审核:陈占龙
校对:牟扬
网站:www.yuehengchina.com Copyright©2023 版权所有:澳门沙金在线平台 - 澳门沙金网站链接


